Druid是阿里开源的数据库连接池,是阿里监控系统Dragoon的副产品,提供了强大的可监控性和基于Filter-Chain的可扩展性。
本篇文章将对Druid数据库连接池的连接创建和销毁进行分析。分析Druid数据库连接池的源码前,需要明确几个概念。
public DruidAbstractDataSource(boolean lockFair) {
lock = new ReentrantLock(lockFair);
notEmpty = lock.newCondition();
empty = lock.newCondition();
}
Druid版本:1.2.11
DruidDataSource连接的创建由CreateConnectionThread线程完成,其run() 方法如下所示。
public void run() {
initedLatch.countDown();
long lastDiscardCount = 0;
int errorCount = 0;
for (; ; ) {
try {
lock.lockInterruptibly();
} catch (InterruptedException e2) {
break;
}
long discardCount = DruidDataSource.this.discardCount;
boolean discardChanged = discardCount - lastDiscardCount > 0;
lastDiscardCount = discardCount;
try {
// emptyWait为true表示生产连接线程需要等待,无需生产连接
boolean emptyWait = true;
// 发生了创建错误,且池中已无连接,且丢弃连接的统计没有改变
// 此时生产连接线程需要生产连接
if (createError != null
&& poolingCount == 0
&& !discardChanged) {
emptyWait = false;
}
if (emptyWait
&& asyncInit && createCount < initialSize) {
emptyWait = false;
}
if (emptyWait) {
// 池中已有连接数大于等于正在等待连接的应用线程数
// 且当前是非keepAlive场景
// 且当前是非连续失败
// 此时生产连接的线程在empty上等待
// keepAlive && activeCount + poolingCount < minIdle时会在shrink()方法中触发emptySingal()来添加连接
// isFailContinuous()返回true表示连续失败,即多次(默认2次)创建物理连接失败
if (poolingCount >= notEmptyWaitThreadCount
&& (!(keepAlive && activeCount + poolingCount < minIdle))
&& !isFailContinuous()
) {
empty.await();
}
// 防止创建超过maxActive数量的连接
if (activeCount + poolingCount >= maxActive) {
empty.await();
continue;
}
}
} catch (InterruptedException e) {
// 省略
} finally {
lock.unlock();
}
PhysicalConnectionInfo connection = null;
try {
connection = createPhysicalConnection();
} catch (SQLException e) {
LOG.error("create connection SQLException, url: " + jdbcUrl
+ ", errorCode " + e.getErrorCode()
+ ", state " + e.getSQLState(), e);
errorCount++;
if (errorCount > connectionErrorRetryAttempts
&& timeBetweenConnectErrorMillis > 0) {
// 多次创建失败
setFailContinuous(true);
// 如果配置了快速失败,就唤醒所有在notEmpty上等待的应用线程
if (failFast) {
lock.lock();
try {
notEmpty.signalAll();
} finally {
lock.unlock();
}
}
if (breakAfterAcquireFailure) {
break;
}
try {
Thread.sleep(timeBetweenConnectErrorMillis);
} catch (InterruptedException interruptEx) {
break;
}
}
} catch (RuntimeException e) {
LOG.error("create connection RuntimeException", e);
setFailContinuous(true);
continue;
} catch (Error e) {
LOG.error("create connection Error", e);
setFailContinuous(true);
break;
}
if (connection == null) {
continue;
}
// 把连接添加到连接池
boolean result = put(connection);
if (!result) {
JdbcUtils.close(connection.getPhysicalConnection());
LOG.info("put physical connection to pool failed.");
}
errorCount = 0;
if (closing || closed) {
break;
}
}
}
CreateConnectionThread的run() 方法整体就是在一个死循环中不断的等待,被唤醒,然后创建线程。当一个物理连接被创建出来后,会调用DruidDataSource#put方法将其放到连接池connections中,put() 方法源码如下所示。
protected boolean put(PhysicalConnectionInfo physicalConnectionInfo) {
DruidConnectionHolder holder = null;
try {
holder = new DruidConnectionHolder(DruidDataSource.this, physicalConnectionInfo);
} catch (SQLException ex) {
// 省略
return false;
}
return put(holder, physicalConnectionInfo.createTaskId, false);
}
private boolean put(DruidConnectionHolder holder,
long createTaskId, boolean checkExists) {
// 涉及到连接池中连接数量改变的操作,都需要加锁
lock.lock();
try {
if (this.closing || this.closed) {
return false;
}
// 池中已有连接数已经大于等于最大连接数,则不再把连接加到连接池并直接返回false
if (poolingCount >= maxActive) {
if (createScheduler != null) {
clearCreateTask(createTaskId);
}
return false;
}
// 检查重复添加
if (checkExists) {
for (int i = 0; i < poolingCount; i++) {
if (connections[i] == holder) {
return false;
}
}
}
// 连接放入连接池
connections[poolingCount] = holder;
// poolingCount++
incrementPoolingCount();
if (poolingCount > poolingPeak) {
poolingPeak = poolingCount;
poolingPeakTime = System.currentTimeMillis();
}
// 唤醒在notEmpty上等待连接的应用线程
notEmpty.signal();
notEmptySignalCount++;
if (createScheduler != null) {
clearCreateTask(createTaskId);
if (poolingCount + createTaskCount < notEmptyWaitThreadCount
&& activeCount + poolingCount + createTaskCount < maxActive) {
emptySignal();
}
}
} finally {
lock.unlock();
}
return true;
}
put() 方法会先将物理连接从PhysicalConnectionInfo中获取出来并封装成一个DruidConnectionHolder,DruidConnectionHolder就是Druid连接池中的连接。新添加的连接会存放在连接池数组connections的poolingCount位置,然后poolingCount会加1,也就是poolingCount代表着连接池中可以获取的连接的数量。
DruidDataSource连接的销毁由DestroyConnectionThread线程完成,其run() 方法如下所示。
public void run() {
// run()方法只要执行了,就调用initedLatch#countDown
initedLatch.countDown();
for (; ; ) {
// 每间隔timeBetweenEvictionRunsMillis执行一次DestroyTask的run()方法
try {
if (closed || closing) {
break;
}
if (timeBetweenEvictionRunsMillis > 0) {
Thread.sleep(timeBetweenEvictionRunsMillis);
} else {
Thread.sleep(1000);
}
if (Thread.interrupted()) {
break;
}
// 执行DestroyTask的run()方法来销毁需要销毁的连接
destroyTask.run();
} catch (InterruptedException e) {
break;
}
}
}
DestroyConnectionThread的run() 方法就是在一个死循环中每间隔timeBetweenEvictionRunsMillis的时间就执行一次DestroyTask的run() 方法。DestroyTask#run方法实现如下所示。
public void run() {
// 根据一系列条件判断并销毁连接
shrink(true, keepAlive);
// RemoveAbandoned机制
if (isRemoveAbandoned()) {
removeAbandoned();
}
}
在DestroyTask#run方法中会调用DruidDataSource#shrink方法来根据设定的条件来判断出需要销毁和保活的连接。DruidDataSource#shrink方法如下所示。
// checkTime参数表示在将一个连接进行销毁前,是否需要判断一下空闲时间
public void shrink(boolean checkTime, boolean keepAlive) {
// 加锁
try {
lock.lockInterruptibly();
} catch (InterruptedException e) {
return;
}
// needFill = keepAlive && poolingCount + activeCount < minIdle
// needFill为true时,会调用empty.signal()唤醒生产连接的线程来生产连接
boolean needFill = false;
// evictCount记录需要销毁的连接数
// keepAliveCount记录需要保活的连接数
int evictCount = 0;
int keepAliveCount = 0;
int fatalErrorIncrement = fatalErrorCount - fatalErrorCountLastShrink;
fatalErrorCountLastShrink = fatalErrorCount;
try {
if (!inited) {
return;
}
// checkCount = 池中已有连接数 - 最小空闲连接数
// 正常情况下,最多能够将前checkCount个连接进行销毁
final int checkCount = poolingCount - minIdle;
final long currentTimeMillis = System.currentTimeMillis();
// 正常情况下,需要遍历池中所有连接
// 从前往后遍历,i为数组索引
for (int i = 0; i < poolingCount; ++i) {
DruidConnectionHolder connection = connections[i];
// 如果发生了致命错误(onFatalError == true)且致命错误发生时间(lastFatalErrorTimeMillis)在连接建立时间之后
// 把连接加入到保活连接数组中
if ((onFatalError || fatalErrorIncrement > 0)
&& (lastFatalErrorTimeMillis > connection.connectTimeMillis)) {
keepAliveConnections[keepAliveCount++] = connection;
continue;
}
if (checkTime) {
// phyTimeoutMillis表示连接的物理存活超时时间,默认值是-1
if (phyTimeoutMillis > 0) {
// phyConnectTimeMillis表示连接的物理存活时间
long phyConnectTimeMillis = currentTimeMillis
- connection.connectTimeMillis;
// 连接的物理存活时间大于phyTimeoutMillis,则将这个连接放入evictConnections数组
if (phyConnectTimeMillis > phyTimeoutMillis) {
evictConnections[evictCount++] = connection;
continue;
}
}
// idleMillis表示连接的空闲时间
long idleMillis = currentTimeMillis - connection.lastActiveTimeMillis;
// minEvictableIdleTimeMillis表示连接允许的最小空闲时间,默认是30分钟
// keepAliveBetweenTimeMillis表示保活间隔时间,默认是2分钟
// 如果连接的空闲时间小于minEvictableIdleTimeMillis且还小于keepAliveBetweenTimeMillis
// 则connections数组中当前连接之后的连接都会满足空闲时间小于minEvictableIdleTimeMillis且还小于keepAliveBetweenTimeMillis
// 此时跳出遍历,不再检查其余的连接
if (idleMillis < minEvictableIdleTimeMillis
&& idleMillis < keepAliveBetweenTimeMillis
) {
break;
}
// 连接的空闲时间大于等于允许的最小空闲时间
if (idleMillis >= minEvictableIdleTimeMillis) {
if (checkTime && i < checkCount) {
// i < checkCount这个条件的理解如下:
// 每次shrink()方法执行时,connections数组中只有索引0到checkCount-1的连接才允许被销毁
// 这样才能保证销毁完连接后,connections数组中至少还有minIdle个连接
evictConnections[evictCount++] = connection;
continue;
} else if (idleMillis > maxEvictableIdleTimeMillis) {
// 如果空闲时间过久,已经大于了允许的最大空闲时间(默认7小时)
// 那么无论如何都要销毁这个连接
evictConnections[evictCount++] = connection;
continue;
}
}
// 如果开启了保活机制,且连接空闲时间大于等于了保活间隔时间
// 此时将连接加入到保活连接数组中
if (keepAlive && idleMillis >= keepAliveBetweenTimeMillis) {
keepAliveConnections[keepAliveCount++] = connection;
}
} else {
// checkTime为false,那么前checkCount个连接直接进行销毁,不再判断这些连接的空闲时间是否超过阈值
if (i < checkCount) {
evictConnections[evictCount++] = connection;
} else {
break;
}
}
}
// removeCount = 销毁连接数 + 保活连接数
// removeCount表示本次从connections数组中拿掉的连接数
// 注:一定是从前往后拿,正常情况下最后minIdle个连接是安全的
int removeCount = evictCount + keepAliveCount;
if (removeCount > 0) {
// [0, 1, 2, 3, 4, null, null, null] -> [3, 4, 2, 3, 4, null, null, null]
System.arraycopy(connections, removeCount, connections, 0, poolingCount - removeCount);
// [3, 4, 2, 3, 4, null, null, null] -> [3, 4, null, null, null, null, null, null, null]
Arrays.fill(connections, poolingCount - removeCount, poolingCount, null);
// 更新池中连接数
poolingCount -= removeCount;
}
keepAliveCheckCount += keepAliveCount;
// 如果池中连接数加上活跃连接数(借出去的连接)小于最小空闲连接数
// 则将needFill设为true,后续需要唤醒生产连接的线程来生产连接
if (keepAlive && poolingCount + activeCount < minIdle) {
needFill = true;
}
} finally {
lock.unlock();
}
if (evictCount > 0) {
// 遍历evictConnections数组,销毁其中的连接
for (int i = 0; i < evictCount; ++i) {
DruidConnectionHolder item = evictConnections[i];
Connection connection = item.getConnection();
JdbcUtils.close(connection);
destroyCountUpdater.incrementAndGet(this);
}
Arrays.fill(evictConnections, null);
}
if (keepAliveCount > 0) {
// 遍历keepAliveConnections数组,对其中的连接做可用性校验
// 校验通过连接就放入connections数组,没通过连接就销毁
for (int i = keepAliveCount - 1; i >= 0; --i) {
DruidConnectionHolder holer = keepAliveConnections[i];
Connection connection = holer.getConnection();
holer.incrementKeepAliveCheckCount();
boolean validate = false;
try {
this.validateConnection(connection);
validate = true;
} catch (Throwable error) {
if (LOG.isDebugEnabled()) {
LOG.debug("keepAliveErr", error);
}
}
boolean discard = !validate;
if (validate) {
holer.lastKeepTimeMillis = System.currentTimeMillis();
boolean putOk = put(holer, 0L, true);
if (!putOk) {
discard = true;
}
}
if (discard) {
try {
connection.close();
} catch (Exception e) {
}
lock.lock();
try {
discardCount++;
if (activeCount + poolingCount <= minIdle) {
emptySignal();
}
} finally {
lock.unlock();
}
}
}
this.getDataSourceStat().addKeepAliveCheckCount(keepAliveCount);
Arrays.fill(keepAliveConnections, null);
}
// 如果needFill为true则唤醒生产连接的线程来生产连接
if (needFill) {
lock.lock();
try {
// 计算需要生产连接的个数
int fillCount = minIdle - (activeCount + poolingCount + createTaskCount);
for (int i = 0; i < fillCount; ++i) {
emptySignal();
}
} finally {
lock.unlock();
}
} else if (onFatalError || fatalErrorIncrement > 0) {
lock.lock();
try {
emptySignal();
} finally {
lock.unlock();
}
}
}
在DruidDataSource#shrink方法中,核心逻辑是遍历connections数组中的连接,并判断这些连接是需要销毁还是需要保活。通常情况下,connections数组中的前checkCount(checkCount = poolingCount - minIdle) 个连接是危险的,因为这些连接只要满足了:空闲时间 >= minEvictableIdleTimeMillis(允许的最小空闲时间),那么就需要被销毁,而connections数组中的最后minIdle个连接是相对安全的,因为这些连接只有在满足:空闲时间 > maxEvictableIdleTimeMillis(允许的最大空闲时间) 时,才会被销毁。这么判断的原因,主要就是需要让连接池里能够保证至少有minIdle个空闲连接可以让应用线程获取。
当确定好了需要销毁和需要保活的连接后,此时会先将connections数组清理,只保留安全的连接,这个过程示意图如下。
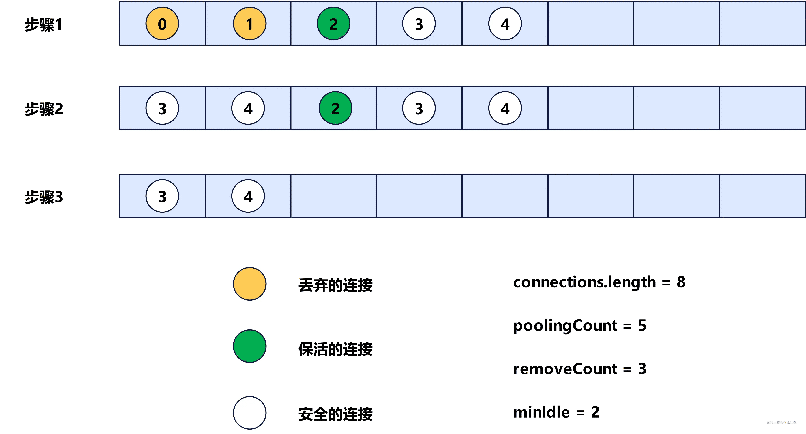
最后,会遍历evictConnections数组,销毁数组中的连接,遍历keepAliveConnections数组,对其中的每个连接做可用性校验,如果校验可用,那么就重新放回connections数组,否则销毁。
连接的创建由一个叫做CreateConnectionThread的线程完成,整体流程就是在一个死循环中不断的等待,被唤醒,然后创建连接。每一个被创建出来的物理连接java.sql.Connection会被封装为一个DruidConnectionHolder,然后存放到connections数组中。
连接的销毁由一个叫做DestroyConnectionThread的线程完成,核心逻辑是周期性的遍历connections数组中的连接,并判断这些连接是需要销毁还是需要保活,需要销毁的连接最后会被物理销毁,需要保活的连接最后会进行一次可用性校验,如果校验不通过,则进行物理销毁。















