布隆过滤器(Bloom Filter)是一种空间效率非常高的随机数据结构,它利用位数组(BitSet)表示一个集合,并通过一定数量的哈希函数将元素映射为位数组中的位置,用于检查一个元素是否属于这个集合。
对于一个元素,通过多个哈希函数生成多个哈希值,将对应的位在位数组中设为 1,若多个哈希值对应的位都为 1,则认为该元素可能在集合中;若至少有一个哈希值对应的位为 0,则该元素一定不在集合中。这种方法可以在较小的空间中实现高效的查找,但可能存在误判率(false positive)。
一个典型的布隆过滤器包含三个参数: 位数组的大小(即存储元素的个数); 哈希函数的个数; 填充因子(即误判率),即将元素数量与位数组大小的比值。
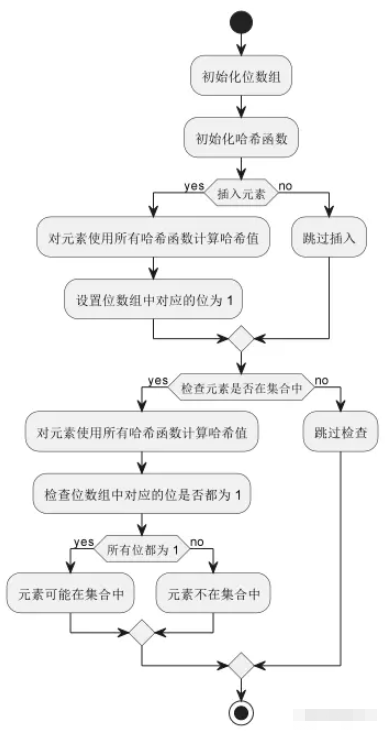
如上图所示: 布隆过滤器的基本操作流程,包括初始化位数组和哈希函数、插入元素、检查元素是否在集合中等。其中,每个元素都会被多个哈希函数映射到位数组中的多个位置,而在检查元素是否在集合中时,需要确保所有对应的位都被设置为 1,才会认为该元素可能在集合中。
垃圾邮件过滤: 将所有的黑名单邮件对应的哈希值在布隆过滤器中对应的位置设为 1,对于每一封新邮件,将其哈希值在布隆过滤器中对应的位置检查是否都为 1,若是,则认为该邮件是垃圾邮件,否则可能是正常邮件;
URL 去重: 将已经抓取的 URL 对应的哈希值在布隆过滤器中对应的位置设为 1,对于每一条新的 URL,将其哈希值在布隆过滤器中对应的位置检查是否都为 1,若是,则认为该 URL 已经抓取过,否则需要进行抓取;
缓存击穿: 将缓存中存在的所有数据对应的哈希值在布隆过滤器中对应的位置设为 1,对于每一个查询的键值,将其哈希值在布隆过滤器中对应的位置检查是否都为 1,若是,则认为该键值存在于缓存中,否则需要从数据库中查询并将其添加到缓存中。
需要注意的是,布隆过滤器的误判率会随着位数组大小的增加而减小,但同时也会增加内存开销和计算时间。 为了方便理解布隆过滤器,下面用java代码实现一个简单的布隆过滤器:
import java.util.BitSet;
import java.util.Random;
public class BloomFilter {
private BitSet bitSet; // 位集,用于存储哈希值
private int bitSetSize; // 位集大小
private int numHashFunctions; // 哈希函数数量
private Random random; // 随机数生成器
// 构造函数,根据期望元素数量和错误率计算位集大小和哈希函数数量
public BloomFilter(int expectedNumItems, double falsePositiveRate) {
this.bitSetSize = optimalBitSetSize(expectedNumItems, falsePositiveRate);
this.numHashFunctions = optimalNumHashFunctions(expectedNumItems, bitSetSize);
this.bitSet = new BitSet(bitSetSize);
this.random = new Random();
}
// 根据期望元素数量和错误率计算最佳位集大小
private int optimalBitSetSize(int expectedNumItems, double falsePositiveRate) {
int bitSetSize = (int) Math.ceil(expectedNumItems * (-Math.log(falsePositiveRate) / Math.pow(Math.log(2), 2)));
return bitSetSize;
}
// 根据期望元素数量和位集大小计算最佳哈希函数数量
private int optimalNumHashFunctions(int expectedNumItems, int bitSetSize) {
int numHashFunctions = (int) Math.ceil((bitSetSize / expectedNumItems) * Math.log(2));
return numHashFunctions;
}
// 添加元素到布隆过滤器中
public void add(String item) {
// 计算哈希值
int[] hashes = createHashes(item.getBytes(), numHashFunctions);
// 将哈希值对应的位设置为 true
for (int hash : hashes) {
bitSet.set(Math.abs(hash % bitSetSize), true);
}
}
// 检查元素是否存在于布隆过滤器中
public boolean contains(String item) {
// 计算哈希值
int[] hashes = createHashes(item.getBytes(), numHashFunctions);
// 检查哈希值对应的位是否都为 true
for (int hash : hashes) {
if (!bitSet.get(Math.abs(hash % bitSetSize))) {
return false;
}
}
return true;
}
// 计算给定数据的哈希值
private int[] createHashes(byte[] data, int numHashes) {
int[] hashes = new int[numHashes];
int hash2 = Math.abs(random.nextInt());
int hash3 = Math.abs(random.nextInt());
for (int i = 0; i < numHashes; i++) {
// 使用两个随机哈希函数计算哈希值
hashes[i] = Math.abs((hash2 * i) + (hash3 * i) + i) % data.length;
}
return hashes;
}
}