
python中pycurl下载失灵
在使用pycurl模块下载文件时,开发者可能会遇到下载无法保存到本地文件的问题。如下代码所示:
url = 'xxx.rar' c = pycurl.Curl() c.setopt(pycurl.URL, url) b = BytesIO() c.setopt(pycurl.WRITEFUNCTION, b.write) c.perform()
在这个代码中,虽然pycurl模块成功下载了文件,但并没有将其保存到本地文件。这是因为代码仅将下载内容保存到了bytesio对象中,而不是写入文件。
要将下载内容写入文件,需要使用c.setopt(pycurl.writedata, open("test.rar", "wb"))来指定文件路径。此外,还需要使用c.setopt(pycurl.followlocation, true)来允许重定向。
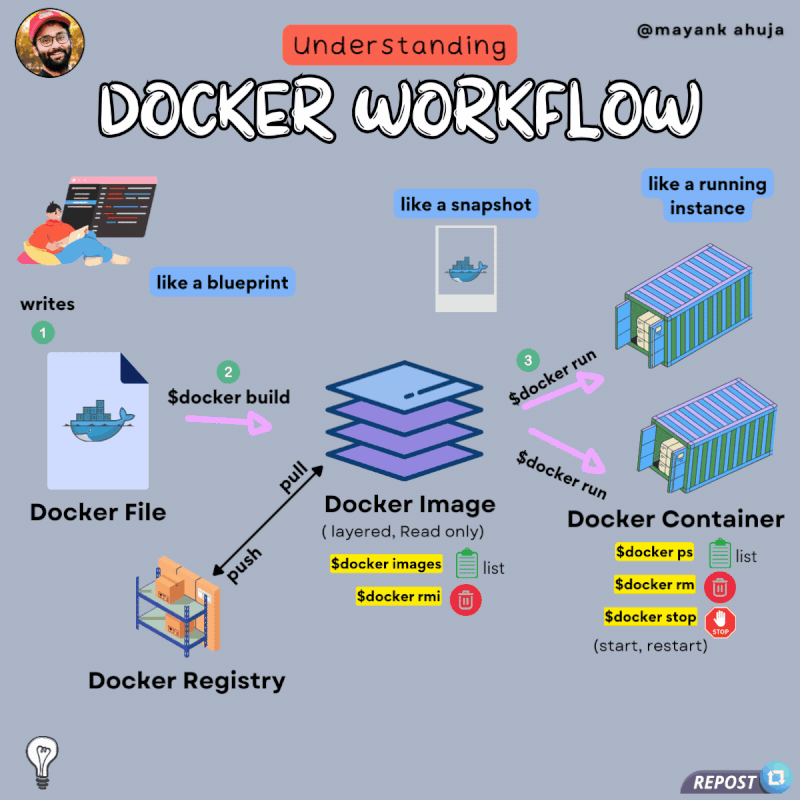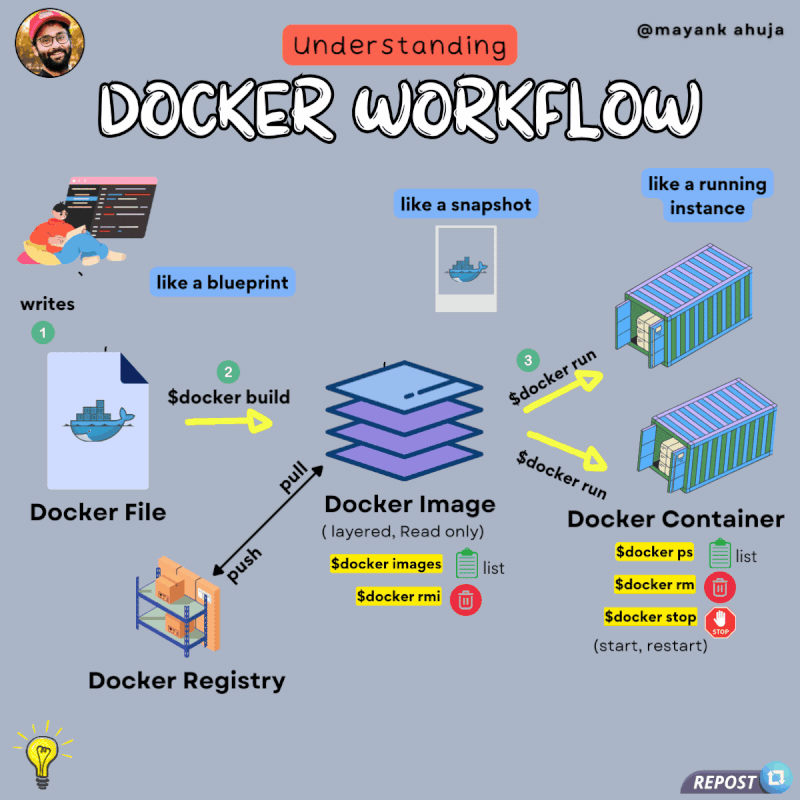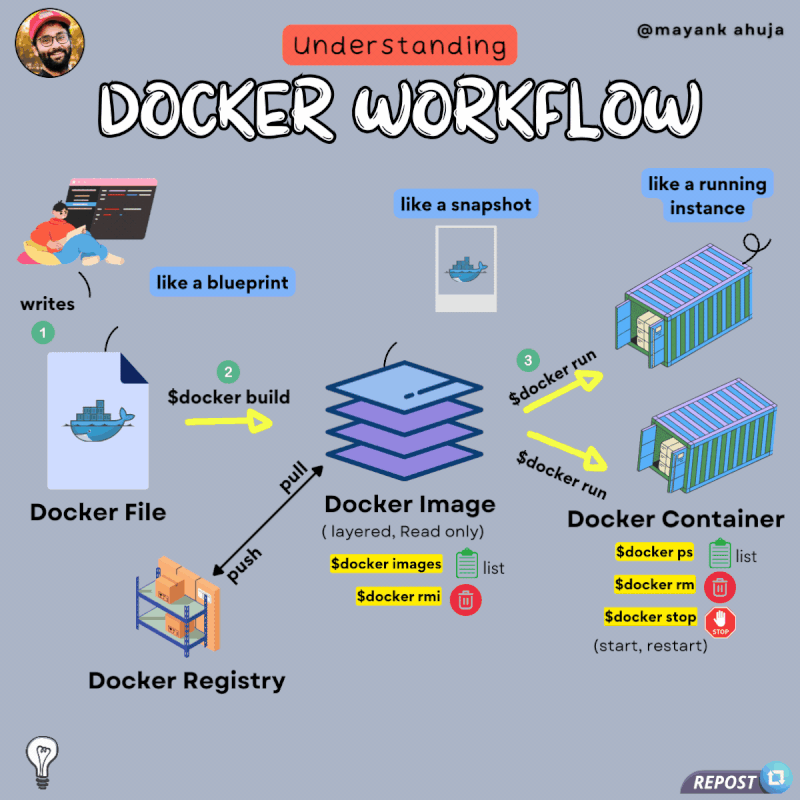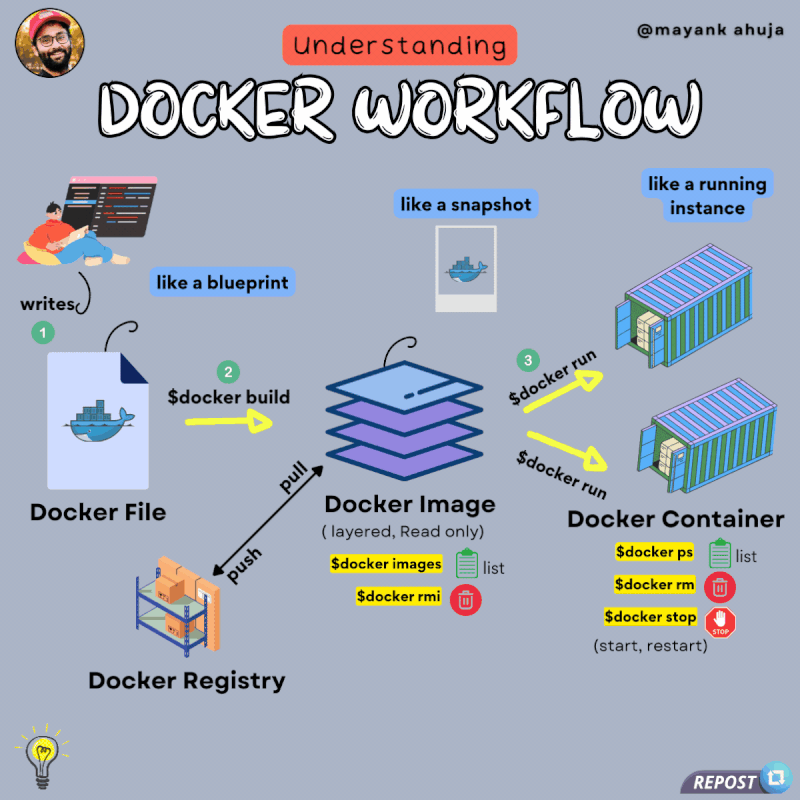
Docker Python Django 初始配置设置

Python 调用 MySQL 语句报错:TypeError: 'NoneType' object is not subscriptable,如何解决?

macOS下PyTorch安装成功却提示ModuleNotFoundError,如何排查?

专用GPU满载,共享GPU闲置?如何充分利用双显卡?

在Scrapy爬虫中使用管道进行数据持久化存储时,如果文件始终为空,可能是由于以下几个常见原因导致的:管道未启用: 确保你在settings.py文件中启用了管道。检查ITEM_PIPELINES配置是否包含了你的管道类,并且优先级设置正确。例如:ITEM_PIPELINES = { 'your_project.pipelines.YourPipeline': 300, }管道逻辑错误: 检查你的管道类中的process_item方法,确保它正确处理了数据并将数据写入文件。常见错误包括文件未打开、

本周经历











