
pycurl判断下载完成并开始新下载
使用pycurl下载多个jar包时,你需要判断当前文件是否下载完成,以便及时开始下载下一个。
判断下载完成
pycurl文档提供了多种方法来判断下载是否完成:
开始新下载
一旦确定当前文件已经下载完成,你可以使用pycurl的以下步骤开始下载下一个文件:
示例代码
以下示例代码演示了如何使用pycurl判断下载完成并开始新下载:
import pycurl, hashlib
urls = ["jar1.zip", "jar2.zip", "jar3.zip"]
hash_values = ["hash1", "hash2", "hash3"]
for i in range(len(urls)):
curl = pycurl.Curl()
curl.setopt(pycurl.URL, urls[i])
curl.setopt(pycurl.WRITEFUNCTION, output_to_file)
curl.setopt(pycurl.FOLLOWLOCATION, True)
# 下载文件
curl.perform()
# 检查文件是否下载完毕
with open("jar1.zip", "rb") as f:
actual_hash = hashlib.sha256(f.read()).hexdigest()
if actual_hash == hash_values[i]:
print("jar1.zip下载完成。")
curl.close()
else:
print("jar1.zip下载失败。")
# 开始下一个下载
# ......
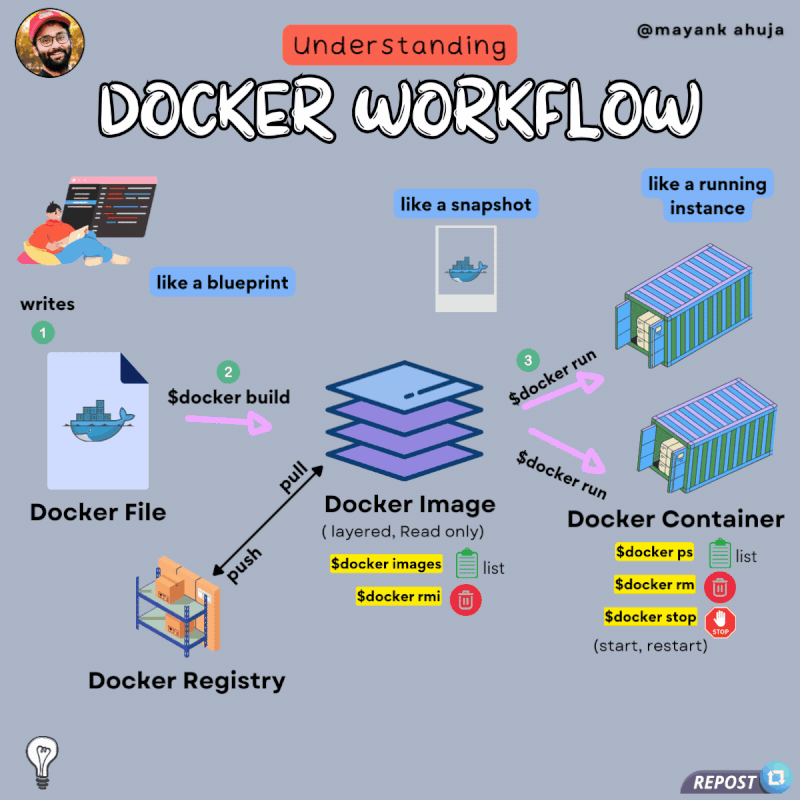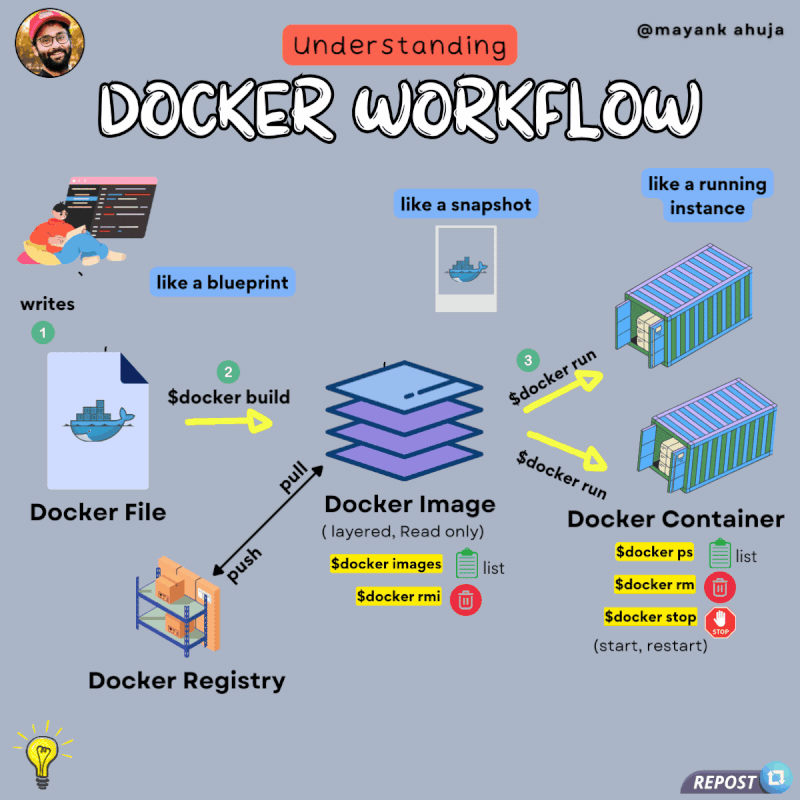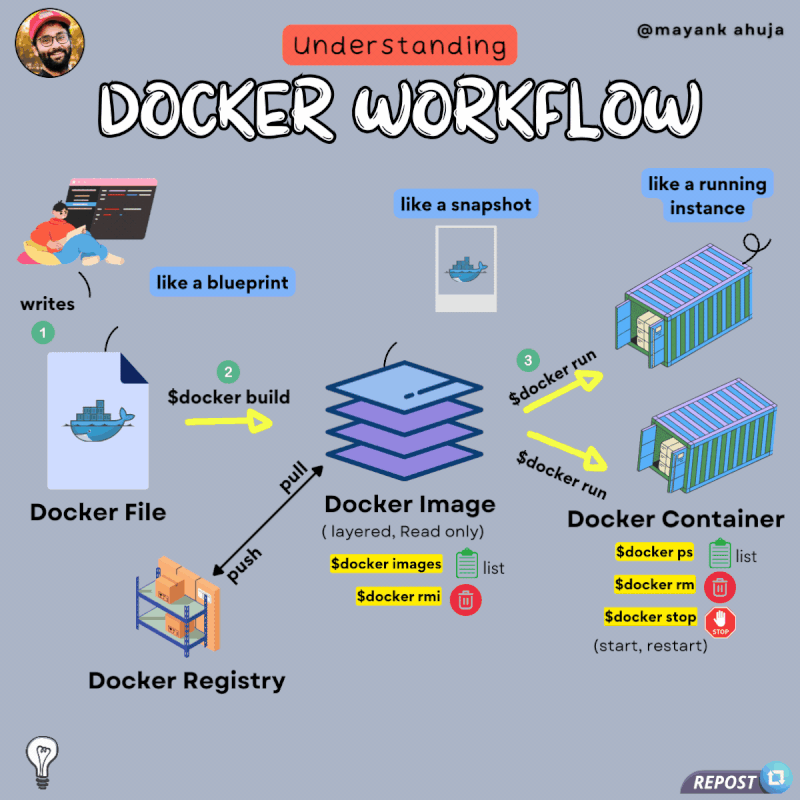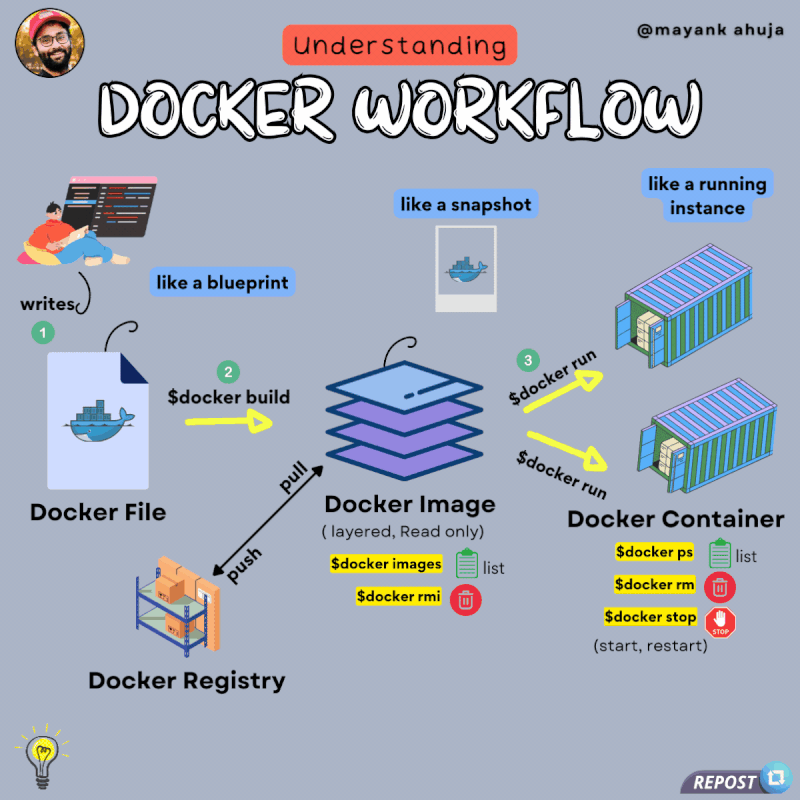
Docker Python Django 初始配置设置

Python 调用 MySQL 语句报错:TypeError: 'NoneType' object is not subscriptable,如何解决?

macOS下PyTorch安装成功却提示ModuleNotFoundError,如何排查?

专用GPU满载,共享GPU闲置?如何充分利用双显卡?

在Scrapy爬虫中使用管道进行数据持久化存储时,如果文件始终为空,可能是由于以下几个常见原因导致的:管道未启用: 确保你在settings.py文件中启用了管道。检查ITEM_PIPELINES配置是否包含了你的管道类,并且优先级设置正确。例如:ITEM_PIPELINES = { 'your_project.pipelines.YourPipeline': 300, }管道逻辑错误: 检查你的管道类中的process_item方法,确保它正确处理了数据并将数据写入文件。常见错误包括文件未打开、

本周经历











