
python 中 print 变量后的判断准确性问题
在使用 selenium 模块操作浏览器时,有的开发者发现直接判断元素的 text 值会出现不准确的情况,需要先 print 一次变量后再判断才准确。这是什么原因呢?
原因可能是变量值还没有被正确赋值。例如:
aaa = driver.find_element_by_xpath('xxxxx').text在这个例子中,aaa 的值尚未被赋值,因为它需要等待元素的 text 属性加载完成。在 print(aaa) 之前进行判断,程序可能会尝试访问一个尚未被正确赋值的变量,导致不准确的结果。
为了解决这个问题,可以在 print(aaa) 之前添加一个延时,例如使用 time.sleep(1),让程序有足够的时间等待变量赋值完成。这样,再进行判断时,变量就能得到正确的赋值。
修改后的代码如下:
aaa = driver.find_element_by_xpath('xxxxx').text
time.sleep(1)
print(aaa)
if 'world' in aaa:
print('in')
else:
print('not in')这样,程序将先等待变量赋值完成,然后再进行判断,保证判断的准确性。

SQL vs NOSQL:选择数据科学的正确数据库

Django网站部署:如何用Nginx优雅地隐藏冗余URL路径?

Python终端彩色输出:如何优雅高效地实现炫酷效果?

在Python中连接MongoDB时,避免解释器关闭时出现的RuntimeError,可以通过确保MongoDB连接在程序结束时正确关闭来实现。以下是解决这一问题的具体方法和代码示例:使用with语句自动管理连接使用with语句可以确保在代码块执行完毕后自动关闭MongoDB连接,从而避免RuntimeError。from pymongo import MongoClient # 使用with语句自动管理连接 with MongoClient('mongodb://localhost:27017/')
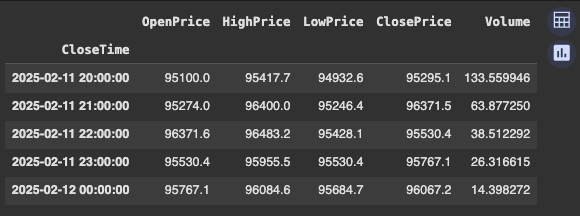
学习熊猫,一个功能强大的库,用于数据可视化,数据操作和分析

Conda环境下Python脚本无法导入库:.py文件如何使用虚拟环境中的Python?











