
使用 multi30k 数据集遇到的 unicodedecodeerror
在使用 torchtext 加载 multi30k 数据集时,遇到 unicodedecodeerror 错误。报错信息提示在 utf-8 编码中无法解码字节 0x80,表明存在编码问题。
根据调查,该问题可能是由于 torchtext 更新导致的。查看 github 仓库中的相关讨论发现,确有其他用户遇到了类似问题。
尝试回退 torchtext 版本至 0.16.1 也不行。此外,其他两个机器翻译数据集(iwslt2016 和 iwslt2017)也无法加载,报错为 404 找不到文件。
解决办法
经过尝试,发现按以下方式加载数据集可以避免 unicodedecodeerror 错误:
train = datasets.Multi30k(root='.data', split='train', language_pair=('de', 'en'))
val = datasets.Multi30k(root='.data', split='valid', language_pair=('de', 'en'))将数据集加载为训练和验证集的单独部分似乎解决了问题。后续测试集无法加载的原因尚不清楚。
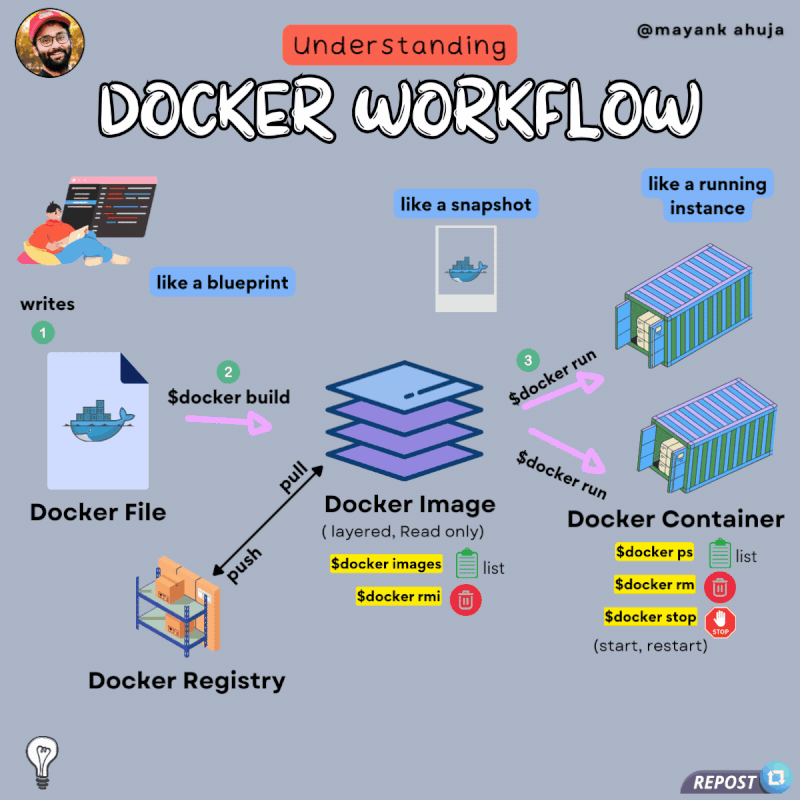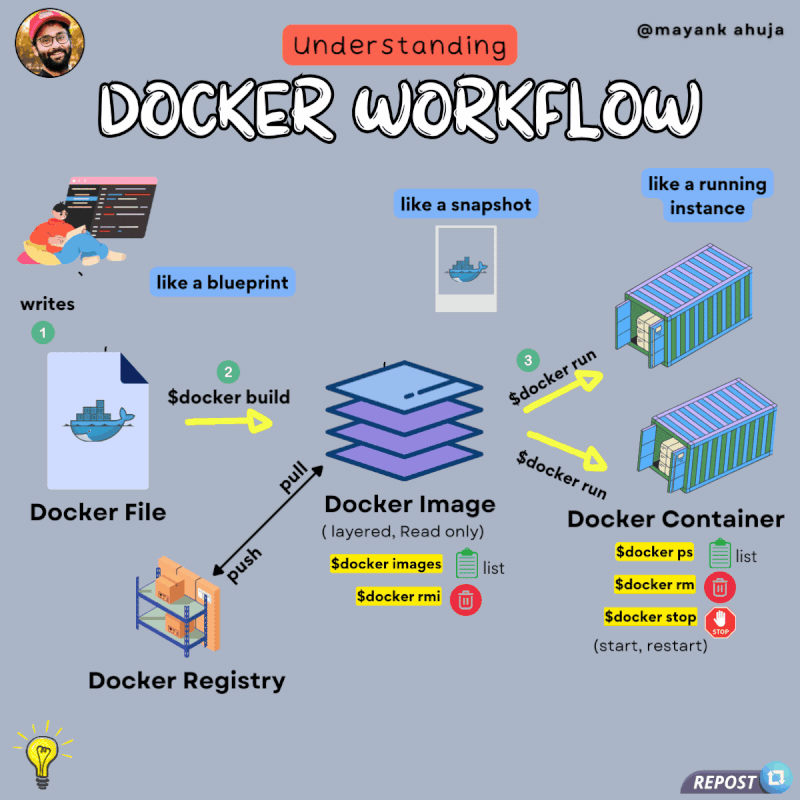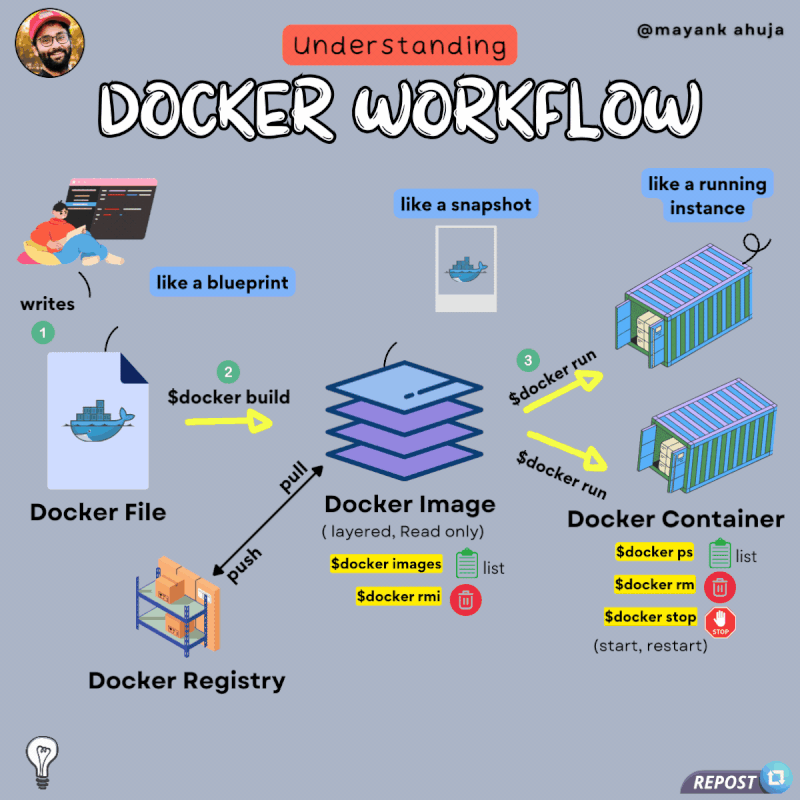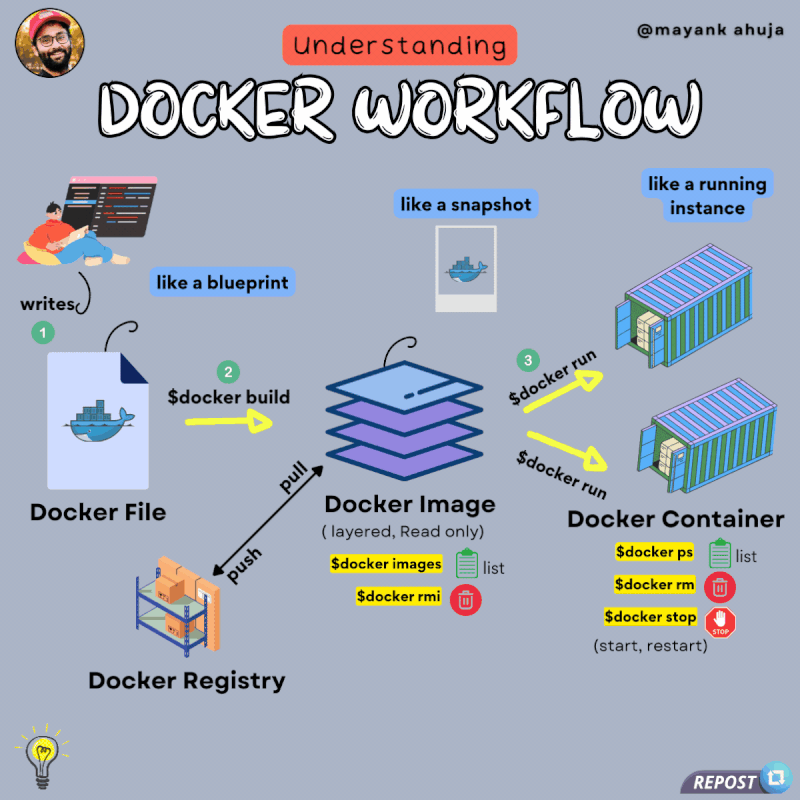
Docker Python Django 初始配置设置

Python 调用 MySQL 语句报错:TypeError: 'NoneType' object is not subscriptable,如何解决?

macOS下PyTorch安装成功却提示ModuleNotFoundError,如何排查?

专用GPU满载,共享GPU闲置?如何充分利用双显卡?

在Scrapy爬虫中使用管道进行数据持久化存储时,如果文件始终为空,可能是由于以下几个常见原因导致的:管道未启用: 确保你在settings.py文件中启用了管道。检查ITEM_PIPELINES配置是否包含了你的管道类,并且优先级设置正确。例如:ITEM_PIPELINES = { 'your_project.pipelines.YourPipeline': 300, }管道逻辑错误: 检查你的管道类中的process_item方法,确保它正确处理了数据并将数据写入文件。常见错误包括文件未打开、

本周经历











