
不借助 pandas 快速分组二维列表
给定一个包含组名和值的二维列表,我们需要按组名对列表进行快速分组,且保持原来的顺序。由于列表较大,我们希望避免使用 pandas,因为它在处理大数据时速度较慢。
我们可以使用现成的库代码来解决这个问题。以下是如何实现的:
def group_name_fun(lst):
last=''
arr=[]
for ii in range(len(lst)):
if not lst[ii][0]==last:
arr.append(ii)
last=lst[ii][0]
arr.append(len(lst))
lst=[lst[arr[ii-1]:arr[ii]] for ii in range(1, len(arr))]
return lst此函数接收一个二维列表,并返回一个分组后的列表。它不使用循环遍历,而是通过比较相邻元素的组名来确定组的边界。
以下是使用示例:
data = [['a',33],['a',0],['a',12],['a',3],['b',3],['b',0],['b',77],['c',1],['c',2],['c',5],['c',0],['c',11],['c',19]] print(group_name_fun(data))
输出:
[[33, 0, 12, 3], [3, 0, 77], [1, 2, 5, 0, 11, 19]]
该函数以 o(n) 的时间复杂度高效地对列表进行分组,其中 n 是列表的长度。
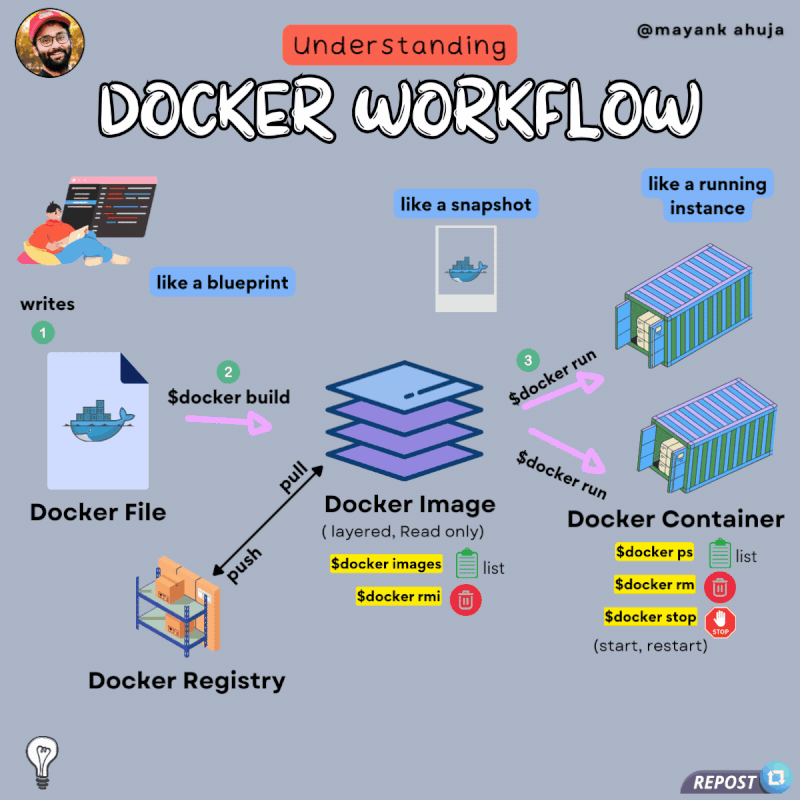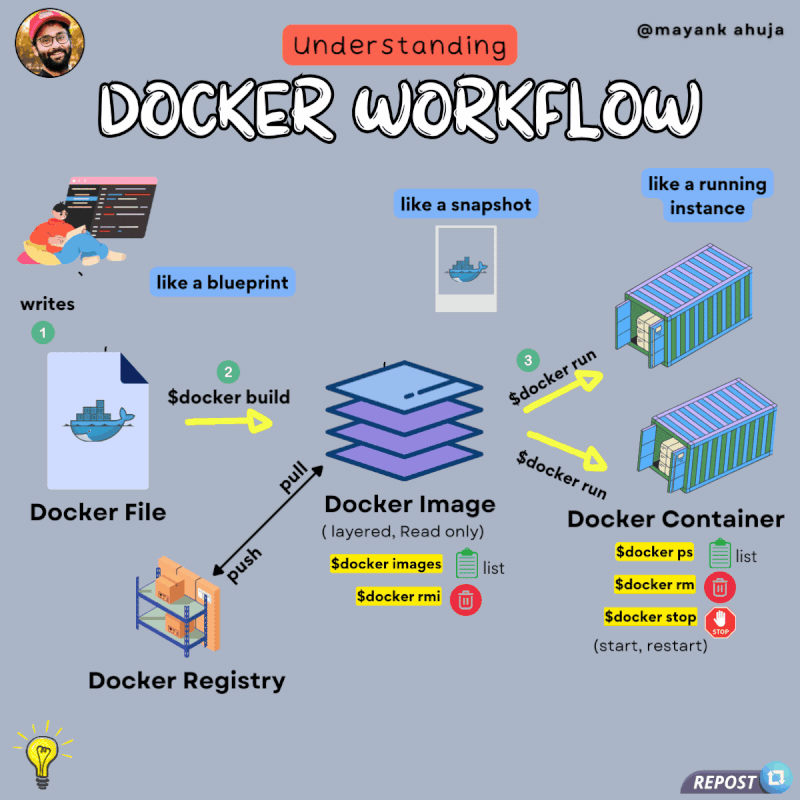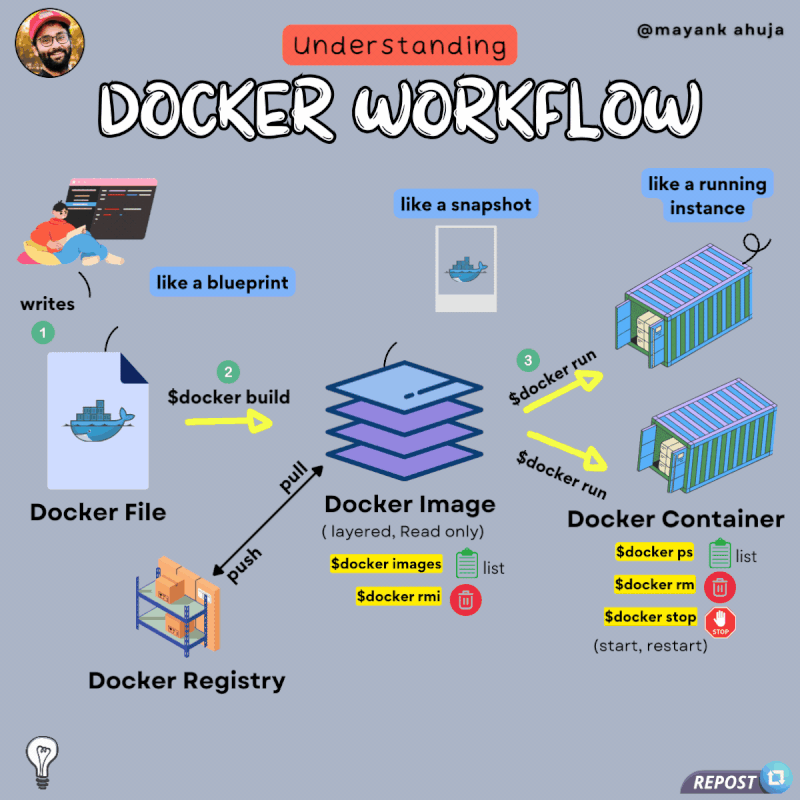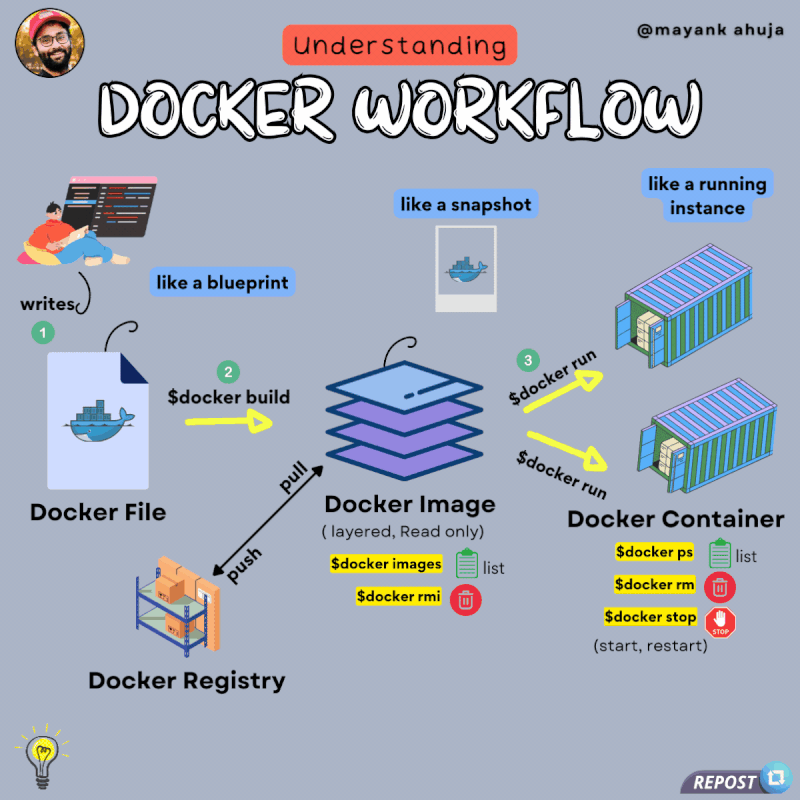
Docker Python Django 初始配置设置

Python 调用 MySQL 语句报错:TypeError: 'NoneType' object is not subscriptable,如何解决?

macOS下PyTorch安装成功却提示ModuleNotFoundError,如何排查?

专用GPU满载,共享GPU闲置?如何充分利用双显卡?

在Scrapy爬虫中使用管道进行数据持久化存储时,如果文件始终为空,可能是由于以下几个常见原因导致的:管道未启用: 确保你在settings.py文件中启用了管道。检查ITEM_PIPELINES配置是否包含了你的管道类,并且优先级设置正确。例如:ITEM_PIPELINES = { 'your_project.pipelines.YourPipeline': 300, }管道逻辑错误: 检查你的管道类中的process_item方法,确保它正确处理了数据并将数据写入文件。常见错误包括文件未打开、

本周经历











