
Pandas高效合并DataFrame:基于索引的优化策略
数据处理中,合并多个DataFrame是常见操作。本文介绍一种高效方法,实现基于日期和名称匹配,将一个DataFrame的数据添加到另一个DataFrame的新列中。
问题背景:
假设有两个DataFrame:df1和df2。df1包含日期(date)和名称(name)列以及其他数据。df2的列名与df1的date列相同,行名与df1的name列相同。目标是根据日期和名称将df2的数据匹配到df1,并在df1中添加名为“result”的新列存储匹配数据。避免低效的循环遍历,需要更优方案。
高效解决方案:
Pandas的join函数结合索引操作,可实现高效匹配。代码如下:
(
df1.set_index(['date', 'name'])
.join(
df2.stack()
.rename_axis(index=['date', 'name'])
.rename('result')
)
)
代码首先将df1的'date'和'name'列设为索引,方便连接。然后,stack()函数将df2转换为Series,创建多层索引('date'和'name')。rename_axis重命名索引,rename为Series命名为'result'。最后,join函数连接处理后的df2和df1,将匹配数据添加到df1的'result'列。此方法利用Pandas的向量化运算,避免循环,显著提高效率,尤其在大数据集处理中。
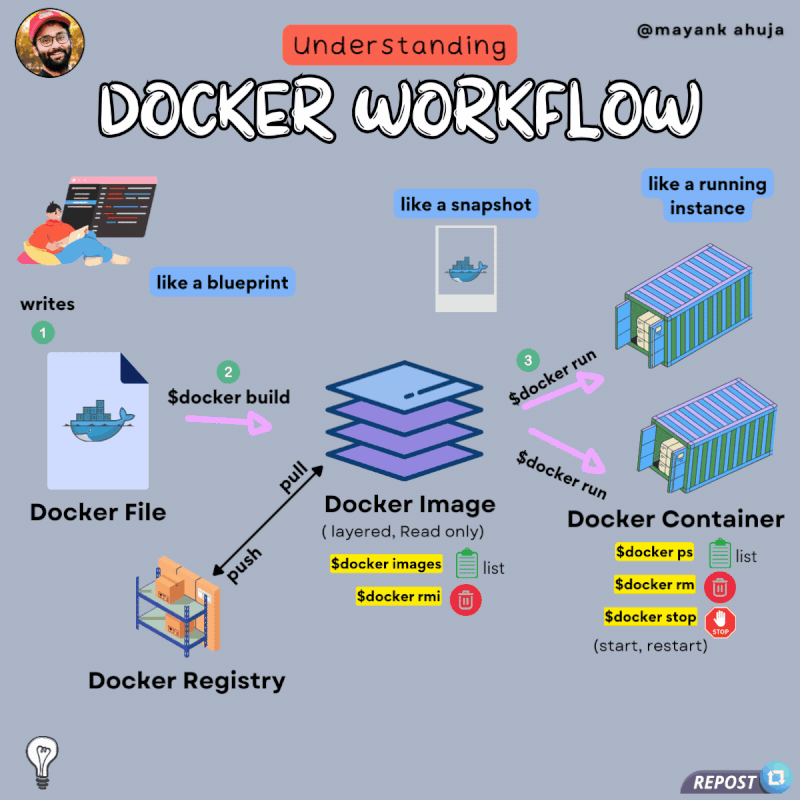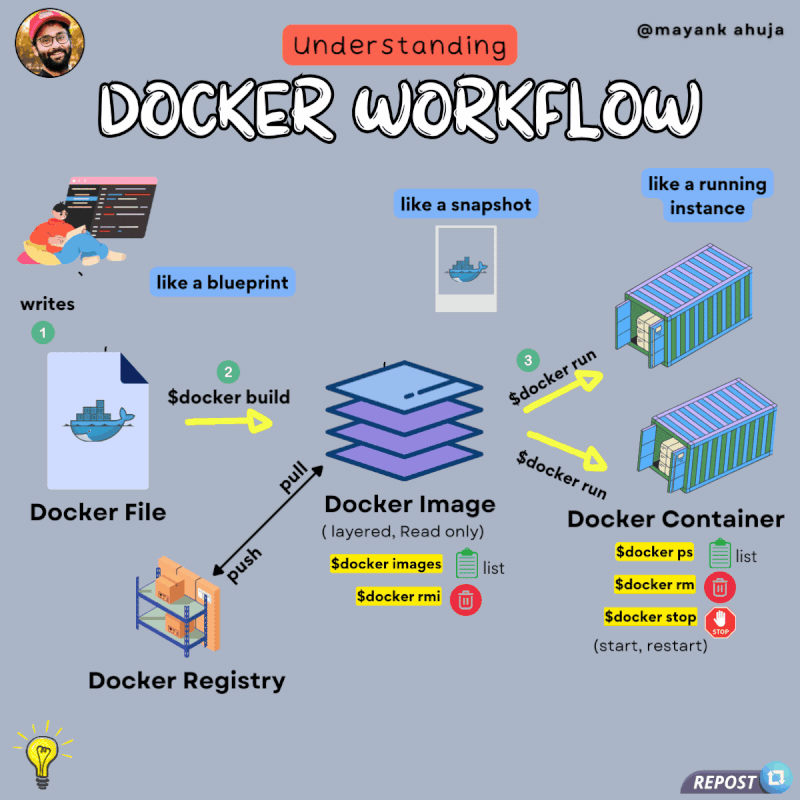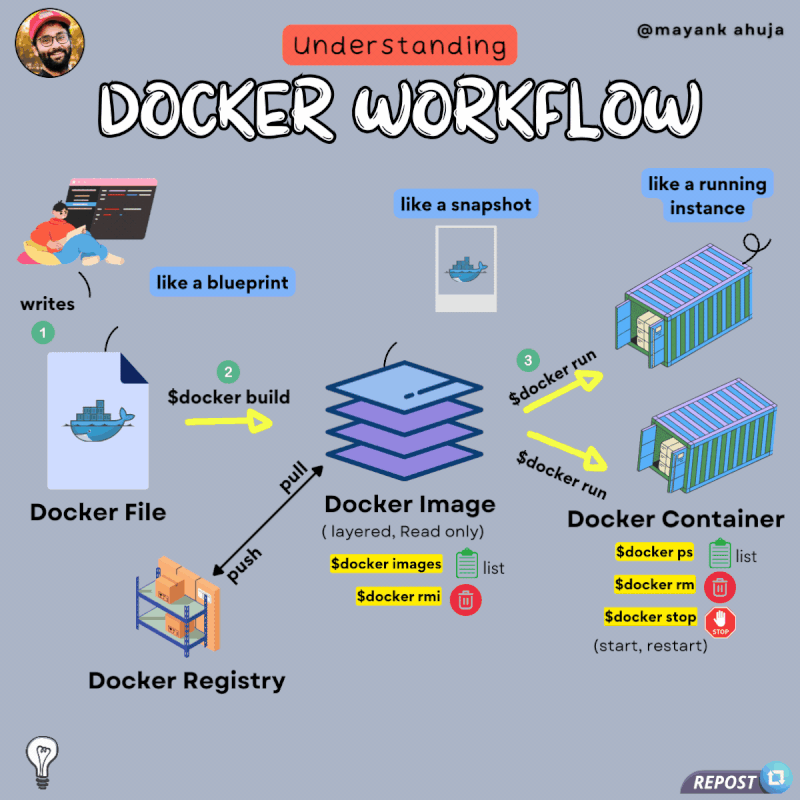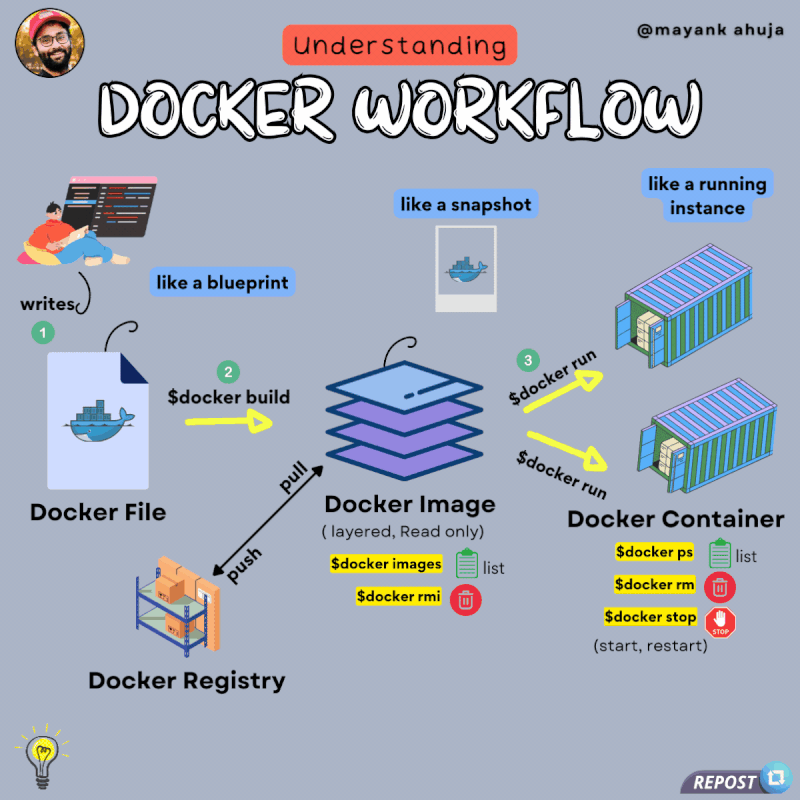
Docker Python Django 初始配置设置

Python 调用 MySQL 语句报错:TypeError: 'NoneType' object is not subscriptable,如何解决?

macOS下PyTorch安装成功却提示ModuleNotFoundError,如何排查?

专用GPU满载,共享GPU闲置?如何充分利用双显卡?

在Scrapy爬虫中使用管道进行数据持久化存储时,如果文件始终为空,可能是由于以下几个常见原因导致的:管道未启用: 确保你在settings.py文件中启用了管道。检查ITEM_PIPELINES配置是否包含了你的管道类,并且优先级设置正确。例如:ITEM_PIPELINES = { 'your_project.pipelines.YourPipeline': 300, }管道逻辑错误: 检查你的管道类中的process_item方法,确保它正确处理了数据并将数据写入文件。常见错误包括文件未打开、

本周经历











