在数据分析和可视化中,层次聚类热图提供了一种强大的工具,可以揭示复杂数据集中的模式和关系。本文探讨了如何使用Python中的Seaborn Clustermap创建层次聚类热图。
为了帮助您理解该过程,我们将利用代码示例逐步引导您完成该过程。我们将指导您如何对数据进行聚类和可视化,这将为您提供有关每个变量之间关系的重要信息。
层次聚类热图是一种可视化技术,用于以热图格式显示数据矩阵,并结合层次聚类。在Python中,Seaborn库提供了一个有用的工具,称为Clustermap,可以创建层次聚类热图。
你是否曾经处理过一个庞大而复杂的数据集,并发现很难识别出数据中的模式或连接?如果是的话,你并不孤单。这是一项艰巨的任务,需要大量的时间和精力。这就是层次聚类的作用所在。这种方法可以根据它们的相似性来组织热图的行和列,从而帮助我们更好地理解数据的不同部分之间的关系。
结果是热图不仅看起来很有吸引力,而且对数据的底层结构也有重大影响。通过组合行和列,我们可以推断它们如何聚集成相似对象的组或族。这有助于识别原始数据中无法立即显现的趋势和联系。
以下是我们将要遵循的步骤,用Seaborn Clustermap在Python中绘制层次聚类热图:
导入必要的库 −
使用 `import seaborn as sns` 导入 Seaborn 库
(可选)使用“import matplotlib.pyplot as plt”导入 Matplotlib 库以进行其他自定义。
加载或准备数据集 −
使用 `sns.load_dataset()` 加载您想要可视化的数据集,或者准备适当格式的自己的数据集。
预处理数据(如果需要)-
执行任何必要的数据预处理步骤,例如重塑或聚合数据,以创建适合热图可视化的矩阵。
创建集群热图 -
使用`sns.clustermap()`函数,将预处理的数据矩阵作为输入。
指定任何其他参数来自定义外观,例如颜色映射(cmap参数)或聚类方法(method参数)。
显示热力图−
如果在步骤1中导入了Matplotlib库,请使用`plt.show()`来显示热图。
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
# Load the inbuilt dataset
data = sns.load_dataset("flights")
# Data preprocessing
data_pivot = data.pivot("month", "year", "passengers")
# Data analysis
monthly_totals = data.groupby("month")["passengers"].sum()
yearly_totals = data.groupby("year")["passengers"].sum()
# Data processing
processed_data = data_pivot.div(monthly_totals, axis=0)
# Create the clustered heatmap using seaborn clustermap
sns.clustermap(processed_data, cmap="YlGnBu")
# Display the heatmap
plt.show()
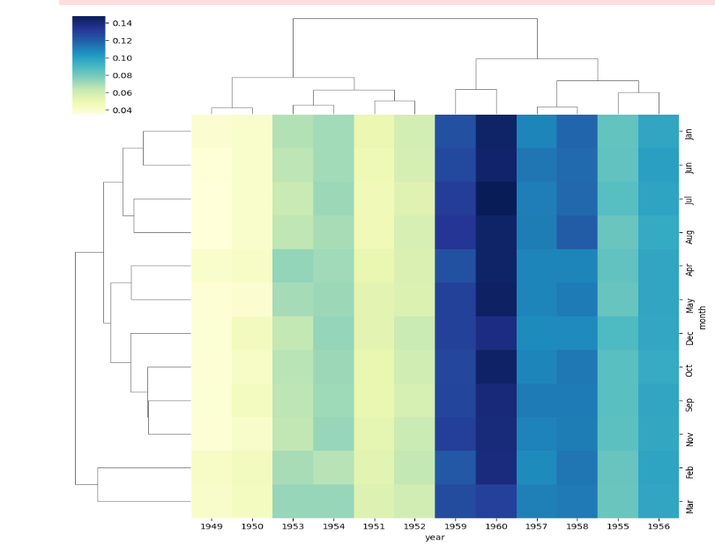
我们使用 Seaborn 的 clustermap() 函数创建分层集群热图,并将数据透视表矩阵作为输入传递。
我们使用cmap参数将颜色映射指定为"YlGnBu"。
提供了额外的自定义选项:
linewidths=0.5:设置树状图中线条的宽度。
figsize=(8, 6):设置生成的热力图图形的大小。
dendrogram_ratio=(0.1, 0.2):调整树状图的高度比例。
我们使用标准 Matplotlib 函数来进一步自定义热图。在本例中,我们使用 plt.title() 设置标题,并分别使用 plt.xlabel() 和 plt.ylabel() 标记 x 轴和 y 轴。
import seaborn as sns
# Load the inbuilt dataset
data = sns.load_dataset("flights")
# Pivot the data to create a matrix for the heatmap
pivot_data = data.pivot("month", "year", "passengers")
# Create the clustered heatmap using seaborn clustermap
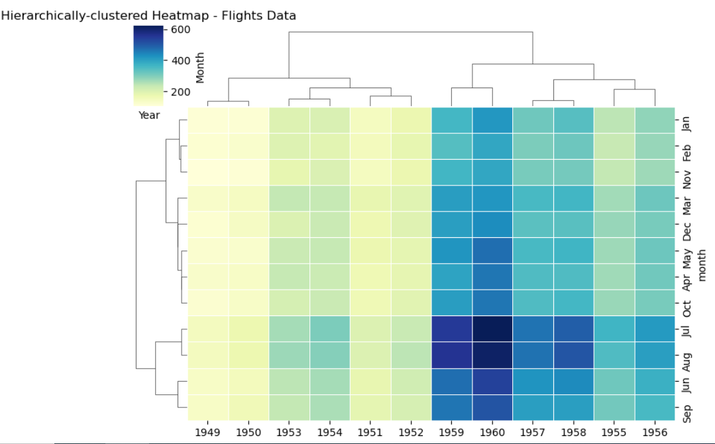
sns.clustermap(pivot_data, cmap="YlGnBu", linewidths=0.5, figsize=(8, 6), dendrogram_ratio=(0.1, 0.2))
# Customize the heatmap
plt.title("Hierarchically-clustered Heatmap - Flights Data")
plt.xlabel("Year")
plt.ylabel("Month")
# Display the heatmap
plt.show()
总之,本文探讨了如何使用Seaborn Clustermap在Python中创建分层聚类热图。通过按照所述步骤,可以轻松地对复杂数据集进行可视化,并揭示数据中的模式和关系。
Seaborn库的clustermap函数提供了灵活性和自定义选项,允许用户根据自己的偏好调整颜色方案、线宽、figsize和树状图比例。